That’s B for billions (of people). Okay, lame title is lame, whatever.
I wrote previously about why Bitcoin’s worth caring about, but if any of that was right, then it naturally leads to the idea that those benefits should be available to many people, not just a few. But what does that actually look like?
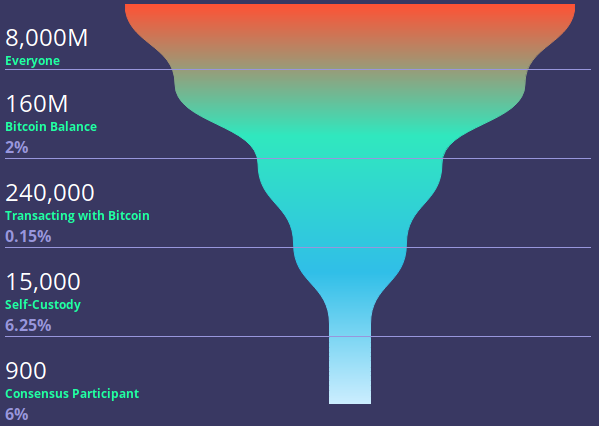
The fundamental challenge with blockchain technology is that every transaction is validated by every user — and as you get more users, you get more transactions, which leads to every (validating) user having to do more work just to keep up, which eventually leads to a crowding out problem: you hit a point where the amount of work you have to do just to keep up with existing usage is more work than prospective new users are willing to do, and adoption stagnates. There are three approaches to resolving that conundrum:
- Just make the tech super efficient.
- Don’t have everyone validate.
- Have most people transact off the blockchain.
Let’s go through those.
Super efficient tech
Technology improves a lot, so maybe we can punt the problem and just have all the necessary software/hardware improvements happen fast enough that adoption never needs to hit a bottleneck: who cares how much work needs to be done if it’s just automatically being dealt with in the background and you never notice it? This is the sort of thing utreexo and zerosync might improve.
I think the fundamental limit these ideas run into is that they can ultimately only reduce the costs related to validating the authorisation of state changes, without being able to compress the state changes themselves — even with zerosync compressing historical state changes, if you want to run protocols like lightning or silent payments, you need to be able to monitor ongoing state changes in a timely fashion, in order to catch attempts to cheat you or just to notice someone making an anonymous donation. Having a billion people transacting directly with each other is already something like 6GB of data a month, even if we assume tech improvements and collapse all the signatures to nothing, and constrain everyone to only participating in a single coinjoin transaction per year. (Maths: 32B input, 32B output, 8B new value; everyone who pays you or who you pay participates in the coinjoin; 1B people * (32+32+8) bytes/tx * 1/12 tx/person/month = 6GB/month).
That’s not completely infeasible by any means, even on mobile or satellite data (for comparison, Bitcoin can currently require 2MB/block * 144 blocks/day * 30 days/month for a total of 8GB/month), but I think it’s still costly enough that many people will decide validating the chain is more effort than it’s worth, particularly if it only gets them one transaction a year on average (so for some, substantially less than that), and choose a different option.
Don’t validate
This is probably the riskiest option: if few people are validating, then thos that do have the potential to collude together to change the rules governing the money. Whether that results in enlightened rule by technocratic elites, or corrupt self-dealing as they optimise the protocol to benefit their own balance sheets, or the whole thing getting shutdown by the SEC as an unregistered security, in practice it’s lost the decentralisation that many of Bitcoin’s potential benefits rely on.
On the other hand, it is probably the easiest option: having the node software provide an API, then just letting multiple users access that API is a pretty normal way to build software, after all.
In this context, the advantage of doing things this way is that you can scale up the cost of validation by orders of magnitude: if you only need dozens, hundreds or even thousands of validators, it’s likely fine if each of those validators have to dedicate a server rack or more to keeping their systems operational.
This can allow increasing the volume or complexity (or both) of the blockchain. For example:
- Bitcoin, pre-segwit: 1MB per 10 minutes
- Bitcoin, post-segwit: ~2MB per 10 minutes
- Ethereum: ~6.4MB per 10 minutes (128kB/12s)
- Chia: ~10MB per 10 minutes (917kB/52s)
- Liquid: ~20MB per 10 minutes (~2MB/60s)
- BCH: 32MB per 10 minutes
- Algorand: 830MB per 10 minutes (5MB/3.7s)
- Solana: 192GB per 10 minutes (128MB/400ms)
(For comparison, 32MB per 10 minutes was also the value Tadge used in 2015 when considering Lightning adoption for up to 280M users)
Doing more than an order of magnitude increase on Bitcoin’s limits in even a moderately decentralised manner seems to already invite significant technical challenges though (eg consider issues faced by Algorand and Solana, even though in practice neither are yet close to their protocol enforced limits).
Saturating a 100Mb/s link would result in about 6GB per 10 minutes (with no redundancy); combining that with the assumed technical improvements from the previous point, might allow a billion people to each participate in 12 coinjoin transactions per day.
Which is great! So long as you don’t mind having created a CBDC where the “central bankers” are the ones able to run validators on dedicated links, and everyone else is just talking to them over an API. If the central bankers here don’t like you spending or receiving money, they can apply KYC rules on API access and lock you out (or can be instructed to by their respective governments); if they decide to change the rules and inflate the supply or steal your coins, then you have to accept that, because you can’t just keep the old system going as you still can’t afford the equipment to run a validating node, let alone a mining one.
Get off the blockchain
Which leaves the final approach: getting most people’s transactions off the Bitcoin blockchain. After all, it’s easy to validate the chain if (almost) nobody is using it. But the question then becomes how do you make Bitcoin usable without using the blockchain?
The founders of Blockstream already came up with the perfect answer to this back in 2014: sidechains. The promise there was that you could just transfer Bitcoin value to be controlled by another blockchain, with a cryptographic guarantee that so long as you obeyed the rules of that other software, then whoever ended up controlling the value on the other software could unilaterally transfer the value back to the Bitcoin blockchain, without needing anyone else’s permission, or anyone else being able to stop them. That would be ideal, of course, but unfortunately it still hasn’t panned out as hoped, and until it does, it seems that there’s likely to remain a need for some form of trusted custodian when moving control of an asset from one blockchain to another.
Lightning on its own provides a different, limited, answer to that question: it can allow you to move your payments off the blockchain, but it still assumes individual users are operating on the blockchain for settlement — in order to rebalance channels, take profits, or deal with attempted fraud. And while we can keep improving that with things like channel factories and off-chain rebalancing, I’m doubtful that that alone can even get settlement down to the “1 tx/person/year” level mentioned above, where technology improvements would potentially let us get the rest of the way.
Another way to answer is to just say “Bitcoin is for saving, not spending”: if people only use Bitcoin for saving, and not for payments, then maybe it’s feasible for people to only deposit or withdraw once every few years, at a similar rate to buying a home. That likely throws away all the possible benefits of Bitcoin other than “inflation resistance”. And while that would still be worthwhile, I’d rather be a little more ambitious.
Of course, a simple and feasible answer is just “use a custodian” — give someone your bitcoin, get an IOU in return, and use that IOU through some other highly scalable API. After all, in this scenario, you’re already implicitly trusting the custodian to redeem the IOU at par sometime later, so it’s not really losing anything to also trust the operator of the scalable API to not screw you over either
That can take a lot of forms, eg:
- funds held via a custodial wallet
- funds held on an exchange
- funds held in fedimint or similar
- funds wrapped in an altcoin token (WBTC on Ethereum, RBTC on Rootstock, L-BTC on Liquid, SoBTC on Solana, etc)
All of those have similar risks, in essence: custodial risks in that there is some privileged entity who may be able to deliberately misappropriate Bitcoin funds that are held in trust and aren’t rightfully theirs, and operational risks, in that you (or your custodian) might lose your funds by pressing the wrong button or by an attacker finding and exploiting a bug in the system (whether that be a web1 backend or a web3 smart contract).
For example RBTC suffered a near-catastrophic operational risk last year, having locked the Bitcoin backing RBTC into a multisig contract that could not be spent from via a standard transaction, resulting in 3 months of downtime for their peg-out service. Or consider the SoBTC bridge, which suffered a “hack” a couple of days after its custodian Alameda collapsed, which, if accurate, was a catastrophic operational error, or, if false, was a catastrophic rug pull. Exchange/wallet hacks and rugpulls likewise have a long and tawdry history.
Whether custodial behaviour is sensible depends first on how much those risks can be reduced. For example, Liquid and fedimint both rely on federations in the hope that it’s less likely a majority of the participants will be willing or able to coordinate a theft. Proof of liabilities and reserves (eg BitMex, cashu, WBTC) is another approach, which can at least allow you as the holder of an IOU to verify that the custodian isn’t already running fractional reserve or operating a ponzi scheme (more IOUs outstanding than BTC available to redeem), even if it doesn’t prevent an eventual rug pull. That probably has some value, since a ponzi scheme is easier to excuse: eg “I’m only stealing a little to make ends meet; I’ll pay it back as soon as things turn around” or “we just don’t have good accounting so may have made a few mistakes, but it was all in good faith”.
If those risks aren’t dealt with, then significant amounts of Bitcoin being held via third-party custodians may prevent Bitcoin from succeeding at many of its goals:
- inflation resistance may be weakened via supply inflation due to unrecognised fractional reserve holdings
- theft resistance may be hard to ensure if trusted custodians frequently turn out to be thieves themselves
- censorship resistance may be weakened if there are only a few custodians
- self-enforcing contracts may be unaffordable if they are only able to be done on the main chain, and not via custodially held coins (eg, due to being held in wallets or exchanges that don’t support programmability, or on alt chains with incompatible programming models)
Decentralised custodians?
But what if, at least for the sake of argument, all those concerns are resolved somehow? For any of this to make sense, there additionally needs to be a way to move funds between custodians without hitting the primary blockchain, at least in the vast majority of cases — otherwise you lock people into having to have a common system with everyone they want to deal with, and you’re back to figuring out how to scale that system, with all the same constraints that applied to Bitcoin’s blockchain originally.
That, at least, seems like a mostly solvable problem: the lightning network already provides a way to chain Bitcoin payments between users without requiring the payer and payee to interact on chain, and extending that to function across multiple chains with a common underlying asset is likely quite feasible. If that approach is sufficient for solving normal payments, then maybe that leaves people who want to participate in self-enforcing contracts more complicated than an HTLC to find a single chain to run their contract but that at least seems likely to be pretty feasible.
What might that world look like? If you assume there are 2000 state updates by custodians per block, and that each custodian has 6 state updates a day on average (a coinjoin or channel factory approach would allow each transaction to involve many custodians, and even with relatively complicated scripts/multisig conditions, 2000 updates per block should be quite feasible), then that would support about 50,000 custodians in total. If a billion Bitcoin users each made use of three custodians, then the average custodian would service about 60,000 customers.
For a user to fully validate both global supply and that their own funds are fully backed, they’d need to validate both the main Bitcoin chain, at a similar cost to today, and (if their custodians make their custodied assets tradable via an altcoin like L-BTC, RBTC or WBTC) may want to verify those chains as well, or otherwise validate their custodians’ claims of liabilities and reserves. But it’s likely that a custodian would need to make many times as many transactions as an end user, so the cost to validate a custodian’s chain that on average might only carry one-third of the transactions of 60,000 users might come to as little as 1% of the effort required to validate the main chain. So the cumulative cost of validating three custodial chains, can probably be arranged to be not too much larger than just validating the Bitcoin main chain. A chain like Liquid, with 10 times the transaction capacity (and validation cost) of Bitcoin, could perhaps support 20,000,000 users who only made one transaction a week on average, for example.
We could convert those numbers to monetary units as well. If you assume that this scenario means that those 50,000 custodians on the main chain are the only entities acting directly the main chain, and divide all 21M bitcoins amongst them, that means that, on average, custodians hold 420 BTC on behalf of their users. If you assume they each spend 1% of total assets in fees per year, then that’s about 4 BTC/block or 400sat/vb in fees. If you assume they fund those fees by collecting fees from people using their IOUs on other blockchains, then each of those blockchains would only need to collect 8000 sats per block, and charge something like 8 msat/vb if they have similar throughput to Bitcoin (compare to Liquid’s current fees of 100msat/vb despite potentially having ten times Bitcoin’s throughput).
Another way of looking at those figures is that, if we were to evolve to roughly this sort of scenario, then whether you’re a custodian or not, the cost of transacting on the main chain would to be pretty expensive: even if you’re willing to spend as much as 1% of your balance in transaction fees a year, and only make one transaction a month, you’ll need to have a balance of about 1 BTC for that to work out. Meanwhile alt chains should be expected to be four or five orders of magnitude cheaper (so if 1 BTC were worth a million dollars, you could reasonably hold $100 or $1000 worth of BTC on an alt chain, and spend something like 8c or 80c per on-chain transaction).
Getting there from here
A world where a billion people are regularly transacting using Bitcoin is quite different from today’s world, of course. An incremental way to look at the above might be to think of it along these lines:
- Each 2MB per 10 minutes worth of transaction data supports perhaps 300,000 users making about 1 tx/day.
- If per-capita usage is lower, then the number of users supported is correspondingly higher (eg, 9,000,000 users making 1 tx/month).
- Increasing utility (individual users wanting to make more transactions) and increasing adoption (more users) both pressure that limit.
- Counting Bitcoin, and RBTC on Rootstock, WBTC on Ethereum and L-BTC on Liquid, the above suggests custodially held Bitcoin can support up to about 5,000,000 users making about 1 tx/day.
- Scaling up to 1 billion users at 1 tx/week would require about 50 clones of Liquid, but that probably creates substantial validation costs. If you limited your Liquid clone to 2MB/10 minutes (matching Bitcoin), you’d need 500 instead; if you reduced the Liquid clone to 200kB/10 minutes, you’d need 5000; or if you reduced it to 20kB/10 minutes (1% of Bitcoin’s size) as suggest above you’d get to 50,000 Liquid clones. (For comparison, Liquid currently seems to average about 11kB/10 minutes — taking blocks from May 2023 and subtracting 1.7kB/block of coinbase/block signature overhead)
At present, I don’t think any of those chains are interoperable over lightning, though at least Liquid potentially could be. I think you could do an atomic swap between any of them, however, allowing you to avoid going on the Bitcoin blockchain, at least, though I’m not sure how easy that is in practice with today’s wallets.
Given Ethereum usage isn’t mostly moving WBTC around, and Rootstock and Liquid have very low usage, that’s certainly more in the way of potential capacity than actual adoption. Even Bitcoin seems to have plenty of spare capacity for graffiti so perhaps it’s within the ballpark to estimate current adoption at perhaps 2,000,000 (on-chain) users making 1 tx/month on average (ie, not counting transactions that are about storing data, moving funds between your own wallets, changing your multisig policy, consolidating utxos, increasing utxo fungibility etc). That compares to about 17,000 public lightning nodes, which would make public lightning operators as making up a bit under 1% of on-chain users. Perhaps there are as many as 10 times that doing lightning over private channels or via a hosted/custodial service, so call it 150,000.
So this is very much “Whose Line is it Anyway?” rules — the numbers are made up, and the ratios don’t matter — but if it were close to reality, what would the path to a billion users look like?
- Get more adoption of lightning for payments (scale up from perhaps 150,000 users now to 1,500,000 users). Somewhere after a 10x increase, Lightning on the main chain will start causing fee pressure, rather than just responding to it.
- Make Liquid much cheaper (drop fee rates from 100msat/vb to 10msat/vb, so that it’s 10x cheaper due to being able to cope with 10x the volume, and an additional 10x cheaper because L-BTC is an IOU). Make it easy and cheap to onboard buy selling small amounts of L-BTC over lightning; likewise make it cheap to exit by buying L-BTC over lightning. Perhaps encourage Liquid functionaries to set a soft limit of
-blockmaxweight=800000 (20% of the current size, for twice Bitcoin’s throughput instead of ten times), to prevent lower fees from resulting in too much spam. - Support Lightning channels that are settled on Liquid for L-BTC (ie, add support to lightning node software for the minor differences in transaction format, and also change the gossip protocol so that you can advertise public channels that aren’t backed by a utxo on the Bitcoin chain). Add support for submarine swaps and the like to go to or from lightning to L-BTC.
- With reduced fee pressure on Liquid, and higher fee pressure on Bitcoin, and software support, that will presumably result in some people moving their channels to be settled on Liquid; if Liquid has 100x or 200x cheaper fees than Bitcoin, that likely means trying Lightning out on Liquid with a small balance will make sense — eg a $200 L-BTC Lightning channel on Liquid with a random stranger, versus a channel worth $20,000 or more in BTC on Bitcoin proper, perhaps made with a counterparty you already have a history with and trust not to disappear on you.
- Increased usage of Liquid will likely reveal unacceptable performance issues; perhaps slow validation or slow IBD, perhaps problems with federation members staying in sync and signing off on new blocks, perhaps problems relaying txs at a sufficient rate to fill blocks, etc. Fix those as they arise.
- Build other cool things, both on Bitcoin, Liquid and other chains. OP_VAULT vaults, alternative payment channels, market makers with other assets, etc. Before too long, either fee pressure on Bitcoin or Liquid will increase to uncomfortable levels, or the fact that the Liquid federation is acting as custodian for a lot of Bitcoin will become annoying.
- At that point, clone Liquid, with a new custodial federation, and a specific target market that’s started to adopt Liquid but isn’t 100% satisfied with it. Tweak the clone’s parameters or its scripting language or the federation membership/policies to be super attractive to that market, find some way of being even more trustworthy at keeping the custodied BTC secure and the chain operational, launch, and get a bunch of traffic from that market.
- From there, rinse and repeat. Make it easy for users to follow validate multiple chains, particularly validating the BTC reservers and the on-chain liabilities, and easy to add a new chain to follow or drop an old chain once they no longer have a balance there.
“Liquid” here doesn’t have to mean Liquid; it could be anything that can support cross-chain payments, such as fedimint, or a bank website, or an Ethereum clone, or a spacechain, or anything else that’s interesting enough to attract a self-sustaining userbase and that you can make trustworthy enough that people will accept giving away custody of their BTC. I picked Liquid as the example, as it’s theoretically straightforward to get proof of liabilities (eg L-BTC liabilities) and reserves (in practice, I can’t find a link or an rpc for this part), it can support self-enforcing contracts, and it shares Bitcoin’s utxo model and scripting language, perhaps making for easier compatibility with Bitcoin itself.
Also perhaps worth noting, that things I paint with a pretty broad brush when I call things “custodial” — OP_VAULT, APO and CTV would likely be enough to allow the “efficient local lightning-factory based banks” I thought about a few years ago; while I’d include that in the class of “custodial” solutions since it only operates efficiently with a trusted custodian, that there is an expensive way of preventing the custodian from cheating might mean you’d class it differently.
(Not worth noting because it should be obvious: all these numbers are made up, and it’s lucky if they’re even in the right ballpark. Don’t try relying on any of them, they’re at most suggestive of the general way in which things might unfold, rather than predictive or reliable)
Fin
Anyway, to move back to generalities, I guess the key ideas are really:
- There’s a bunch of room to grow non-custodial Lightning and on-chain activity on Bitcoin now — for Lightning, something like 10x should be plausible, but likely also 2x growth (or more) for everything else, perhaps more if there are also technology/efficiency improvements deployed. So PTLCs, eltoo, channel factories, OP_VAULT, silent payments, payjoins, etc would all fit in here.
- But the headroom there isn’t unlimited — expect it to show up as fee pressure and backlogs and less ability to quickly resolve transaction storms. And that will in turn make it hard and expensive for people with small stacks to continue to do self-custody on the main chain. At that point, acquiring new high value users means pricing out existing low value users.
- Moving those users onto cheaper chains that can only deal in BTC IOUs kind of sucks, but it’s better than the alternatives: either having them use something worse still, or nobody being able to verify that the big players are still following the rules.
Perhaps one way to think of this is as the gentrification of the Bitcoin blockchain; with the plebs and bohemians forced to move to new neighbourhoods and create new and thriving art scenes there? If so, a key difference between real estate gentrification is that in this analogy, moving out in this sense is a way of defending the existing characteristics of the neighbourhood, rather than abandoning it to the whims of corporatism. And, of course, the Bitcoin itself always remains in Bitcoin’s utxo set, even if its day to day activity is recorded elsewhere. But in any event, that’s a tomorrow problem, not a today problem.
Anyway, to conclude, here are some links to a couple of the conversations that provoked me to thinking about this: with @kcalvinalvinn prompted by @gladstein; and this between @fiatjaf and @brian_trollz. Also some potentially amusing related thoughts on scaling that go in a different direction from back when BTC was 100x cheaper.






{kind=link}