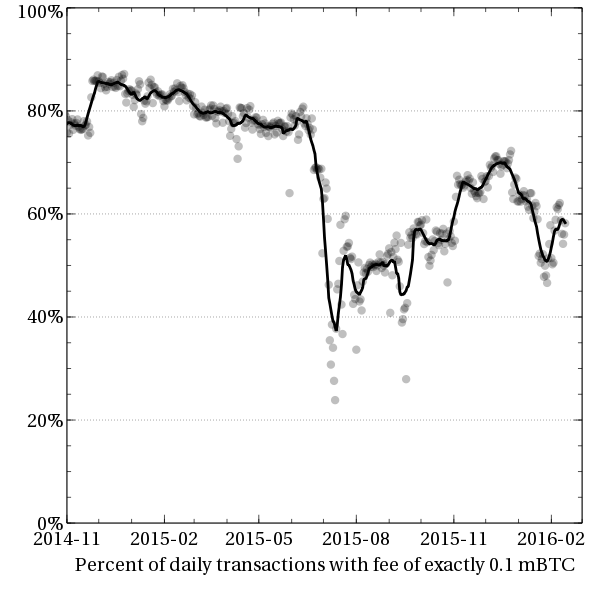
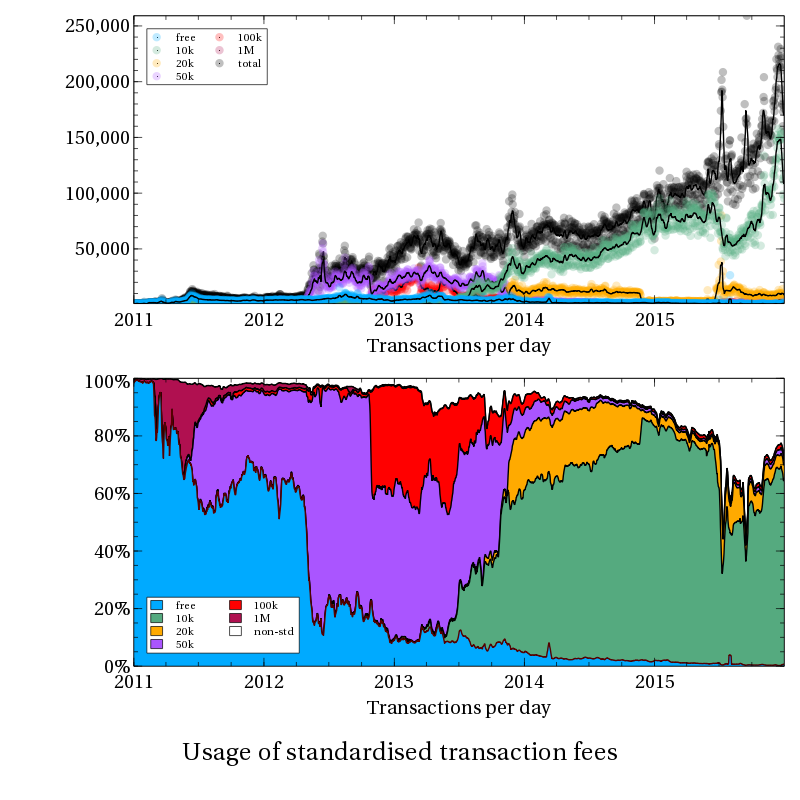
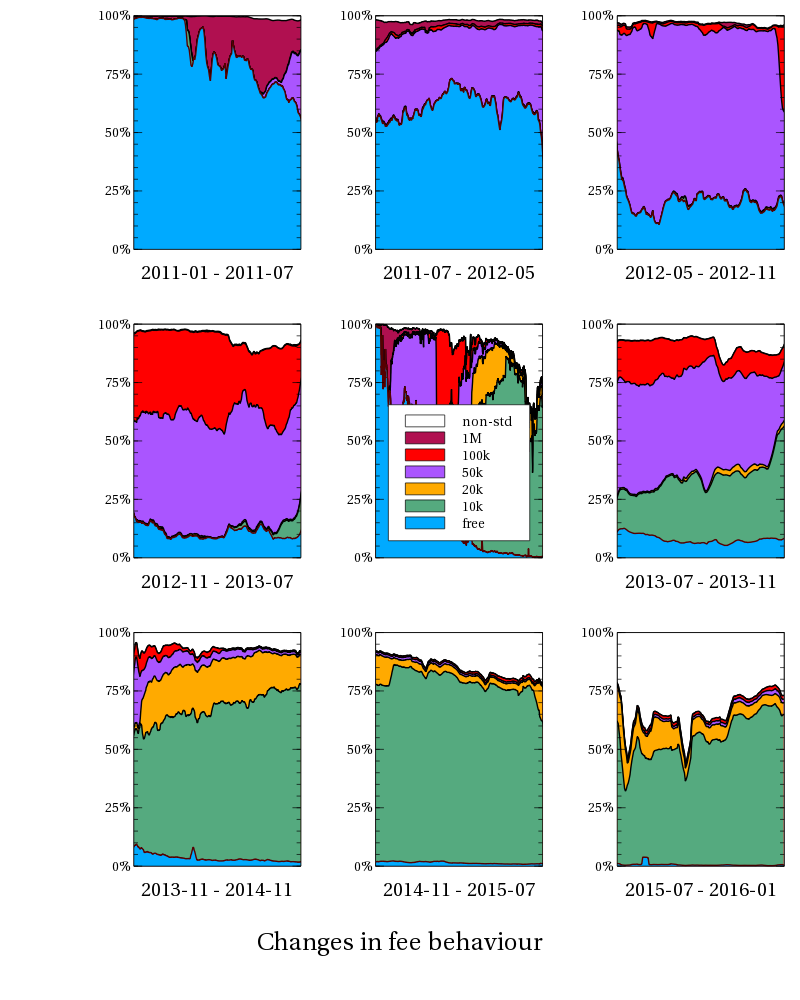
So the first question: is ASICBoost use plausible in the real world?
There are plenty of claims that it’s not:
- “Much conspiracy around today. I don’t believe SegWit non-activation has anything to do with AsicBoost!” – Timo Hanke, one of the patent applicants, on twitter
- “there’s absolutely nothing but baseless accusations flying around” – Emin Gun Sirer’s take, linked from the Bitmain statement
- “no company would ever produce a chip that would have a switch in to hide that it’s actually an ASICboost chip.” – Sam Cole formerly of KNCMiner which went bankrupt due to being unable to compete with Bitmain in 2016
- “I believe their claim about not activating ASICBoost. It is very small money for them.” – Guy Corem of SpoonDoolies, who independently discovered ASICBoost
- “No one is even using Asicboost.” – Roger Ver (/u/memorydealers) on reddit
A lot of these claims don’t actually match reality though: ASICBoost is implemented in Bitmain miners sold to the public, and since it defaults to off, a switch to hide it is obviously easily possible since it’s disabled by default, contradicting Sam Cole’s take. There’s plenty of circumstantial evidence of ASICBoost-related transaction structuring in blocks, contradicting the basis on which Emin Gun Sirer’s dismisses the claims. The 15%-30% improvement claims that Guy Corem and Sam Cole cite are certainly large enough to be worth looking into — and Bitmain confirms to have done on testnet. Even Guy Corem’s claim that they only amount to $2,000,000 in savings per year rather than $100,000,000 seems like a reason to expect it to be in use, rather than so little that you wouldn’t bother.
If ASICBoost weren’t in use on mainnet it would probably be relatively straightforward to prove that: Bitmain could publish the benchmarks results they got when testing on testnet, and why that proved not to be worth doing on mainnet, and provide instructions for their customers on how to reproduce their results, for instance. Or Bitmain and others could support efforts to block ASICBoost from being used on mainnet, to ensure no one else uses it, for the greater good of the network — if, as they claim, they’re already not using it, this would come at no cost to them.
To me, much of the rhetoric that’s being passed around seems to be a much better match for what you would expect if ASICBoost were in use, than if it was not. In detail:
- If ASICBoost were in use, and no one had any reason to hide it being used, then people would admit to using it, and would do so by using bits in the block version.
- If ASICBoost were in use, but people had strong reasons to hide that fact, then people would claim not to be using it for a variety of reasons, but those explanations would not stand up to more than casual analysis.
- If ASICBoost were not in use, and it was fairly easy to see there is no benefit to it, then people would be happy to share their reasoning for not using it in detail, and this reasoning would be able to be confirmed independently.
- If ASICBoost were not in use, but the reasons why it is not useful require significant research efforts, then keeping the detailed reasoning private may act as a competitive advantage.
The first scenario can be easily verified, and does not match reality. Likewise the third scenario does not (at least in my opinion) match reality; as noted above, many of the explanations presented are superficial at best, contradict each other, or simply fall apart on even a cursory analysis. Unfortunately that rules out assuming good faith — either people are lying about using ASICBoost, or just dissembling about why they’re not using it. Working out which of those is most likely requires coming to our own conclusion on whether ASICBoost makes sense.
I think Jimmy Song had some good posts on that topic. His first, on Bitmain’s ASICBoost claims finds some plausible examples of ASICBoost testing on testnet, however this was corrected in the comments as having been performed by Timo Hanke, rather than Bitmain. Having a look at other blocks’ version fields on testnet seems to indicate that there hasn’t been much other fiddling of version fields, so presumably whatever testing of ASICBoost was done by Bitmain, fiddling with the version field was not used; but that in turn implies that Bitmain must have been testing covert ASICBoost on testnet, assuming their claim to have tested it on testnet is true in the first place (they could quite reasonably have used a private testnet instead). Two later posts, on profitability and ASICBoost and Bitmain’s profitability in particular, go into more detail, mostly supporting Guy Corem’s analysis mentioned above. Perhaps interestingly, Jimmy Song also made a proposal to the bitcoin-dev shortly after Greg’s original post revealing ASICBoost and prior to these posts; that proposal would have endorsed use of ASICBoost on mainnet, making it cheaper and compatible with segwit, but would also have made use of ASICBoost readily apparent to both other miners and patent holders.
It seems to me there are three different ways to look at the maths here, and because this is an economics question, each of them give a different result:
- Greg’s maths splits miners into two groups each with 50% of hashpower. One group, which is unable to use ASICBoost is assumed to be operating at almost zero profit, so their costs to mine bitcoins are only barely below the revenue they get from selling the bitcoin they mine. Using this assumption, the costs of running mining equipment are calculated by taking the number of bitcoin mined per year (365*24*6*12.5=657k), multiplying that by the price at the time ($1100), and halving the costs because each group only mines half the chain. This gives a cost of mining for the non-ASICBoost group of $361M per year. The other group, which uses ASICBoost, then gains a 30% advantage in costs, so only pays 70%, or $252M, a comparative saving of approximately $100M per annum. This saving is directly proportional to hashrate and ASICBoost advantage, so using Guy Corem’s figures of 13.2% hashrate and 15% advantage, this reduces from $95M to $66M, saving about $29M per annum.
- Guy Corem’s maths estimates Bitmain’s figures directly: looking at the AntPool hashpower share, he estimates 500PH/s in hashpower (or 13.2%); he uses the specs of the AntMiner S9 to determine power usage (0.1 J/GH); he looks at electricity prices in China and estimates $0.03 per kWh; and he estimates the ASICBoost advantage to be 15%. This gives a total cost of 500M GH/s * 0.1 J/GH / 1000 W/kW * $0.03 per kWh * 24 * 365 which is $13.14 M per annum, so a 15% saving is just under $2M per annum. If you assume that the hashpower was 50% and ASICBoost gave a 30% advantage instead, this equates to about 1900 PH/s, and gives a benefit of just under $15M per annum. In order to get the $100M figure to match Greg’s result, you would also need to increase electricity costs by a factor of six, from 3c per kWH to 20c per kWH.
- The approach I prefer is to compare what your hashpower would be keeping costs constant and work out the difference in revenue: for example, if you’re spending $13M per annum in electricity, what is your profit with ASICBoost versus without (assuming that the difficulty retargets appropriately, but no one else changes their mining behaviour). Following this line of thought, if you have 500PH/s with ASICBoost giving you a 30% boost, then without ASICBoost, you have 384 PH/s (500/1.3). If that was 13.2% of hashpower, then the remaining 86.8% of hashpower is 3288 PH/s, so when you stop using ASICBoost and a retarget occurs, total hashpower is now 3672 PH/s (384+3288), and your percentage is now 10.5%. Because mining revenue is simply proportional to hashpower, this amounts to a loss of 2.7% of the total bitcoin reward, or just under $20M per year. If you match Greg’s assumptions (50% hashpower, 30% benefit) that leads to an estimate of $47M per annum; if you match Guy Corem’s assumptions (13.2% hashpower, 15% benefit) it leads to an estimate of just under $11M per annum.
So like I said, that’s three different answers in each of two scenarios: Guy’s low end assumption of 13.2% hashpower and a 15% advantage to ASICBoost gives figures of $29M/$2M/$11M; while Greg’s high end assumptions of 50% hashpower and 30% advantage give figures of $100M/$15M/$47M. The differences in assumptions there is obviously pretty important.
I don’t find the assumptions behind Greg’s maths realistic: in essence, it assumes that mining be so competitive that it is barely profitable even in the short term. However, if that were the case, then nobody would be able to invest in new mining hardware, because they would not recoup their investment. In addition, even if at some point mining were not profitable, increases in the price of bitcoin would change that, and the price of bitcoin has been increasing over recent months. Beyond that, it also assumes electricity prices do not vary between miners — if only the marginal miner is not profitable, it may be that some miners have lower costs and therefore are profitable; and indeed this is likely the case, because electricity prices vary over time due to both seasonal and economic factors. The method Greg uses does is useful for establishing an upper limit, however: the only way ASICBoost could offer more savings than Greg’s estimate would be if every block mined produced less revenue than it cost in electricity, and miners were making a loss on every block. (This doesn’t mean $100M is an upper limit however — that estimate was current in April, but the price of bitcoin has more than doubled since then, so the current upper bound via Greg’s maths would be about $236M per year)
A downside to Guy’s method from the point of view of outside analysis is that it requires more information: you need to know the efficiency of the miners being used and the cost of electricity, and any error in those estimates will be reflected in your final figure. In particular, the cost of electricity needs to be a “whole lifecycle” cost — if it costs 3c/kWh to supply electricity, but you also need to spend an additional 5c/kWh in cooling in order to keep your data-centre operating, then you need to use a figure of 8c/kWh to get useful results. This likely provides a good lower bound estimate however: using ASICBoost will save you energy, and if you forget to account for cooling or some other important factor, then your estimate will be too low; but that will still serve as a loose lower bound. This estimate also changes over time however; while it doesn’t depend on price, it does depend on deployed hashpower — since total hashrate has risen from around 3700 PH/s in April to around 6200 PH/s today, if Bitmain’s hashrate has risen proportionally, it has gone from 500 PH/s to 837 PH/s, and an ASICBoost advantage of 15% means power cost savings have gone from $2M to $3.3M per year; or if Bitmain has instead maintained control of 50% of hashrate at 30% advantage, the savings have gone from $15M to $25M per year.
The key difference between my method and both Greg’s and Guy’s is that they implicitly assume that consuming more electricity is viable, and costs simply increase proportionally; whereas my method assumes that this is not viable, and instead that sufficient mining hardware has been deployed that power consumption is already constrained by some other factor. This might be due to reaching the limit of what the power company can supply, or the rating of the wiring in the data centre, or it might be due to the cooling capacity, or fire risk, or some other factor. For an operation spanning multiple data centres this may be the case for some locations but not others — older data centres may be maxed out, while newer data centres are still being populated and may have excess capacity, for example. If setting up new data centres is not too difficult, it might also be true in the short term, but not true in the longer term — that is having each miner use more power due to disabling ASICBoost might require shutting some miners down initially, but they may be able to be shifted to other sites over the course of a few weeks or month, and restarted there, though this would require taking into account additional hosting costs beyond electricity and cooling. As such, I think this is a fairly reasonable way to produce an plausible estimate, and it’s the one I’ll be using. Note that it depends on the bitcoin price, so the estimates this method produces have also risen since April, going from $11M to $24M per annum (13.2% hash, 15% advantage) or from $47M to $103M (50% hash, 30% advantage).
The way ASICBoost works is by allowing you to save a few steps: normally when trying to generate a proof of work, you have to do essentially six steps:
- A = Expand( Chunk1 )
- B = Compress( A, 0 )
- C = Expand( Chunk2 )
- D = Compress( C, B )
- E = Expand( D )
- F = Compress( E )
The expected process is to do steps (1,2) once, then do steps (3,4,5,6) about four billion (or more) times, until you get a useful answer. You do this process in parallel across many different chips. ASICBoost changes this process by observing that step (3) is independent of steps (1,2) — so by finding a variety of Chunk1s — call them Chunk1-A, Chunk1-B, Chunk1-C and Chunk1-D that are each compatible with a common Chunk2. In that case, you do steps (1,2) four times for each different Chunk1, then do step (3) four billion (or more) times, and do steps (4,5,6) 16 billion (or more) times, to get four times the work, while saving 12 billion (or more) iterations of step (3). Depending on the number of Chunk1’s you set yourself up to find, and the relative weight of the Expand versus Compress steps, this comes to (n-1)/n / 2 / (1+c/e), where n is the number of different Chunk1’s you have. If you take the weight of Expand and Compress steps as about equal, it simplifies to 25%*(n-1)/n, and with n=4, this is 18.75%. As such, an ASICBoost advantage of about 20% seems reasonably practical to me. At 50% hash and 20% advantage, my estimates for ASICBoost’s value are $33M in April, and $72M today.
So as to the question of whether you’d use ASICBoost, I think the answer is a clear yes: the lower end estimate has risen from $2M to $3.3M per year, and since Bitmain have acknowledged that AntMiner’s support ASICBoost in hardware already, the only additional cost is finding collisions which may not be completely trivial, but is not difficult and is easily automated.
If the benefit is only in this range, however, this does not provide a plausible explanation for opposing segwit: having the Bitcoin industry come to a consensus about how to move forward would likely increase the bitcoin price substantially, definitely increasing Bitmain’s mining revenue — even a 2% increase in price would cover their additional costs. However, as above, I believe this is only a lower bound, and a more reasonable estimate is on the order of $11M-$47M as of April or $24M-$103M as of today. This is a much more serious range, and would require an 11%-25% increase in price to not be an outright loss; and a far more attractive proposition would be to find a compromise position that both allows the industry to move forward (increasing the price) and allows ASICBoost to remain operational (maintaining the cost savings / revenue boost).
It’s possible to take a different approach to analysing the cost-effectiveness of mining given how much you need to pay in electricity costs. If you have access to a lot of power at a flat rate, can deal with other hosting issues, can expand (or reduce) your mining infrastructure substantially, and have some degree of influence in how much hashpower other miners can deploy, then you can derive a formula for what proportion of hashpower is most profitable for you to control.
In particular, if your costs are determined by an electricity (and cooling, etc) price, E, in dollars per kWh and performance, r, in Joules per gigahash, then given your hashrate, h in terahash/second, your power usage in watts is (h*1e3*r), and you run this for 600 seconds on average between each block (h*r*6e5 Ws), which you divide by 3.6M to convert to kWh (h*r/6), then multiply by your electricity cost to get a dollar figure (h*r*E/6). Your revenue depends on the hashrate of the everyone else, which we’ll call g, and on average you receive (p*R*h/(h+g)) every 600 seconds where p is the price of Bitcoin in dollars and R is the reward (subsidy and fees) you receive from a block. Your profit is just the difference, namely h*(p*R/(h+g) – r*E/6). Assuming you’re able to manufacture and deploy hashrate relatively easily, at least in comparison to everyone else, you can optimise your profit by varying h while the other variables (bitcoin price p, block reward R, miner performance r, electricity cost E, and external hashpower g) remain constant (ie, set the derivative of that formula with respect to h to zero and simplify) which gives a result of 6gpR/Er = (g+h)^2.
This is solvable for h (square root both sides and subtract g), but if we assume Bitmain is clever and well funded enough to have already essentially optimised their profits, we can get a better sense of what this means. Since g+h is just the total bitcoin hashrate, if we call that t, and divide both sides, we get 6gpR/Ert = t, or g/t = (Ert)/(6pR), which tells us what proportion of hashrate the rest of the network can have (g/t) if Bitmain has optimised its profits, or, alternative we can work out h/t = 1-g/t = 1-(Ert)/(6pR) which tells us what proportion of hashrate Bitmain will have if it has optimised its profits. Plugging in E=$0.03 per kWH, r=0.1 J/GH, t=6e6 TH/s, p=$2400/BTC, R=12.5 BTC gives a figure of 0.9 – so given the current state of the network, and Guy Corem’s cost estimate, Bitmain would optimise its day to day profits by controlling 90% of mining hashrate. I’m not convinced $0.03 is an entirely reasonable figure, though — my inclination is to suspect something like $0.08 per kWh is more reasonable; but even so, that only reduces Bitmain’s optimal control to around 73%.
Because of that incentive structure, if Bitmain’s current hashrate is lower than that amount, then lowering manufacturing costs for own-use miners by 15% (per Sam Cole’s estimates) and lowering ongoing costs by 15%-30% by using ASICBoost could have a compounding effect by making it easier to quickly expand. (It’s not clear to me that manufacturing a line of ASICBoost-only miners to reduce manufacturing costs by 15% necessarily makes sense. For one thing, this would come at a cost of not being able to mine with them while they are state of the art, then sell them on to customers once a more efficient model has been developed, which seems like it might be a good way to manage inventory. For another, it vastly increases the impact of ASICBoost not being available: rather than simply increasing electricity costs by 15%-30%, it would mean reducing output to 10%-25% of what it was, likely rendering the hardware immediately obsolete)
Using the same formula, it’s possible to work out a ratio of bitcoin price (p) to hashrate (t) that makes it suboptimal for a manufacturer to control a hashrate majority (at least just due to normal mining income): h/t < 0.5, 1-Ert/6pR < 0.5, so t > 3pR/Er. Plugging in p=2400, R=12.5, e=0.08, r=0.1, this gives a total hash rate of 11.25M TH/s, almost double the current hash rate. This hashrate target would obviously increase as the bitcoin price increases, halve if the block reward halves (if a fall in the inflation subsidy is not compensated by a corresponding increase in fee income eg), increase if the efficiency of mining hardware increases, and decrease if the cost of electricity increases. For a simpler formula, assuming the best hosting price is $0.08 per kWh, and while the Antminer S9’s efficiency at 0.1 J/GH is state of the art, and the block reward is 12.5 BTC, the global hashrate in TH/s should be at least around 5000 times the price (ie 3R/Er = 4787.5, near enough to 5000).
Note that this target also sets a limit on the range at which mining can be profitable: if it’s just barely better to allow other people to control >50% of miners when your cost of electricity is E, then for someone else whose cost of electricity is 2*E or more, optimal profit is when other people control 100% of hashrate, that is, you don’t mine at all. Thus if the best large scale hosting globally costs $0.08/kWh, then either mining is not profitable anywhere that hosting costs $0.16/kWh or more, or there’s strong centralisation pressure for a mining hardware manufacturer with access to the cheapest electrictiy to control more than 50% of hashrate. Likewise, if Bitmain really can do hosting at $0.03/kWh, then either they’re incentivised to try to control over 50% of hashpower, or mining is unprofitable at $0.06/kWh and above.
If Bitmain (or any mining ASIC manufacturer) is supplying the majority of new hashrate, they actually have a fairly straightforward way of achieving that goal: if they dedicate 50-70% of each batch of ASICs built for their own use, and sell the rest, with the retail price of the sold miners sufficient to cover the manufacturing cost of the entire batch, then cashflow will mostly take care of itself. At $1200 retail price and $500 manufacturing costs (per Jimmy Song’s numbers), that strategy would imply targeting control of up to about 58% of total hashpower. The above formula would imply that’s the profit-maximising target at the current total hashrate and price if your average hosting cost is about $0.13 per kWh. (Those figures obviously rely heavily on the accuracy of the estimated manufacturing costs of mining hardware; at $400 per unit and $1200 retail, that would be 67% of hashpower, and about $0.09 per kWh)
Strategies like the above are also why this analysis doesn’t apply to miners who buy their hardware rather from a vendor, rather than building their own: because every time they increase their own hash rate (h), the external hashrate (g) also increases as a direct result, it is not valid to assume that g is constant when optimising h, so the partial derivative and optimisation is in turn invalid, and the final result is not applicable.
Bitmain’s mining pool, AntPool, obviously doesn’t directly account for 58% or more of total hashpower; though currently they’re the pool with the most hashpower at about 20%. As I understand it, Bitmain is also known to control at least BTC.com and ConnectBTC which add another 7.6%. The other “Emergent Consensus” supporting pools (Bitcoin.com, BTC.top, ViaBTC) account for about 22% of hashpower, however, which brings the total to just under 50%, roughly the right ballpark — and an additional 8% or 9% could easily be pointed at other public pools like slush or f2pool. Whether the “emergent consensus” pools are aligned due to common ownership and contractual obligations or simply similar interests is debatable, though. ViaBTC is funded by Bitmain, and Canoe was built and sold by Bitmain, which means strong contractual ties might exist, however Jihan Wu, Bitmain’s co-founder, has disclaimed equity ties to BTC.top. Bitcoin.com is owned by Roger Ver, but I haven’t come across anything implying a business relationship between Bitmain and Bitcoin.com beyond supplier and customer. However John McAffee’s apparently forthcoming MGT mining pool is both partnered with Bitmain and advised by Roger Ver, so the existence of tighter ties may be plausible.
It seems likely to me that Bitmain is actually behaving more altruistically than is economically rational according to the analysis above: while it seems likely to me that Bitcoin.com, BTC.top, ViaBTC and Canoe have strong ties to Bitmain and that Bitmain likely has a high level of influence — whether due to contracts, business relationships or simply due to the loyalty and friendship — this nevertheless implies less control over the hashpower than direct ownership and management, and likely less profit. This could be due to a number of factors: perhaps Bitmain really is already sufficiently profitable from mining that they’re focusing on building their business in other ways; perhaps they feel the risks of centralised mining power are too high (and would ultimately be a risk to their long term profits) and are doing their best to ensure that mining power is decentralised while still trying to maximise their return to their investors; perhaps the rate of expansion implied by this analysis requires more investment than they can cover from their cashflow, and additional hashpower is funded by new investors who are simply assigned ownership of a new mining pool, which may helps Bitmain’s investors assure themselves they aren’t being duped by a pyramid scheme and gives more of an appearance of decentralisation.
It seems to me therefore there could be a variety of ways in which Bitmain may have influence over a majority of hashpower:
- Direct ownership and control, that is being obscured in order to avoid an economic backlash that might result from people realising over 50% of hashpower is controlled by one group
- Contractual control despite independent ownership, such that customers of Bitmain are committed to follow Bitmain’s lead when signalling blocks in order to maintain access to their existing hardware, or to be able to purchase additional hardware (an account on reddit appearing to belong to the GBMiners pool has suggested this is the case)
- Contractual control due to offering essential ongoing services, eg support for physical hosting, or some form of mining pool services — maintaining the infrastructure for covert ASICBoost may be technically complex enough that Bitmain’s customers cannot maintain it themselves, but that Bitmain could relatively easily supply as an ongoing service to their top customers.
- Contractual influence via leasing arrangements rather than sale of hardware — if hardware is leased to customers, or financing is provided, Bitmain could retain some control of the hardware until the leasing or financing term is complete, despite not having ownership
- Coordinated investment resulting in cartel-like behaviour — even if there is no contractual relationship where Bitmain controls some of its customers in some manner, it may be that forming a cartel of a few top miners allows those miners to increase profits; in that case rather than a single firm having control of over 50% of hashrate, a single cartel does. While this is technically different, it does not seem likely to be an improvement in practice. If such a cartel exists, its members will not have any reason to compete against each other until it has maximised its profits, with control of more than 70% of the hashrate.
So, conclusions:
- ASICBoost is worth using if you are able to. Bitmain is able to.
- Nothing I’ve seen suggest Bitmain is economically clueless; so since ASICBoost is worth doing, and Bitmain is able to use it on mainnet, Bitmain are using it on mainnet.
- Independently of ASICBoost, Bitmain’s most profitable course of action seems to be to control somewhere in the range of 50%-80% of the global hashrate at current prices and overall level of mining.
- The distribution of hashrate between mining pools aligned with Bitmain in various ways makes it plausible, though not certain, that this may already be the case in some form.
- If all this hashrate is benefiting from ASICBoost, then my estimate is that the value of ASICBoost is currently about $72M per annum
- Avoiding dominant mining manufacturers tending towards supermajority control of hashrate requires either a high global hashrate or a relatively low price — the hashrate in TH/s should be about 5000 times the price in dollars.
- The current price is about $2400 USD/BTC, so the corresponding hashrate to prevent centralisation at that price point is 12M TH/s. Conversely, the current hashrate is about 6M TH/s, so the maximum price that doesn’t cause untenable centralisation pressure is $1200 USD/BTC.